The other ninety-eight percent
What the exome era of genomics reveals about subquadratic attention — and the belief trap that follows a good, necessary compromise.

Where I Started
On what a field has to relearn when its compromises get too productive.
I was reading about subquadratic attention the other day, the work on getting transformers to stop comparing every token to every other token, and I had the kind of déjà vu you can't place at first. It took a minute. Then it landed. I'd watched this before, in genome sequencing.
The Exome Compromise
The first human genome was one of the most expensive things science had ever attempted. The Human Genome Project ran for thirteen years, spanned twenty institutes across three continents, and cost around $2.7 billion. Reading a genome wasn't just hard. It was the kind of hard that makes you ask whether it's worth doing at all.
Then the technology improved, and a practical question showed up: do we actually need the whole thing?
Most of the disease-causing mutations we knew about sat in the protein-coding regions, the exome, one or two percent of the genome. If that's where the answers were, you could read just that part and get most of the clinical value for a fraction of the cost. The exome wasn't cheap. It was viable, in a way the whole genome wasn't yet. For years it was the right call: not everything, but enough, at a price you could actually pay.
That was a good compromise. It worked. And that's where it gets interesting.
How Junk DNA Got Its Name
Because the field got very productive inside that one or two percent. So productive that a belief crept in alongside the practice. If the answers were in the exome, maybe the answers were only in the exome. The rest of the genome, the other ninety-eight percent, picked up a name: junk DNA. Not "the part we can't afford to read yet." Junk. A silent ocean of repeats and broken-down genes we'd decided wasn't doing much, largely because we'd gotten so good at finding what we needed without it.
That belief lasted a long time. It was wrong.
The Other Ninety-Eight Percent
As costs fell, people went back out into the ninety-eight percent, and it turned out not to be junk at all. The non-coding regions were closer to the operating system of the cell. Regulatory elements, deciding when and where and how much genes get used. We hadn't been looking at noise. We'd been looking away from the part we couldn't yet afford to study, and calling our budget a fact about biology.
Today that work is mainstream. Whole-genome sequencing is becoming routine. The thing that took thirteen years now runs in about an hour, and the reason to do it isn't just that it's cheap. It's that there's real structure out there worth interrogating, structure the exome era couldn't have seen. We didn't go back to the whole genome only because we could. We went back because there was something there.
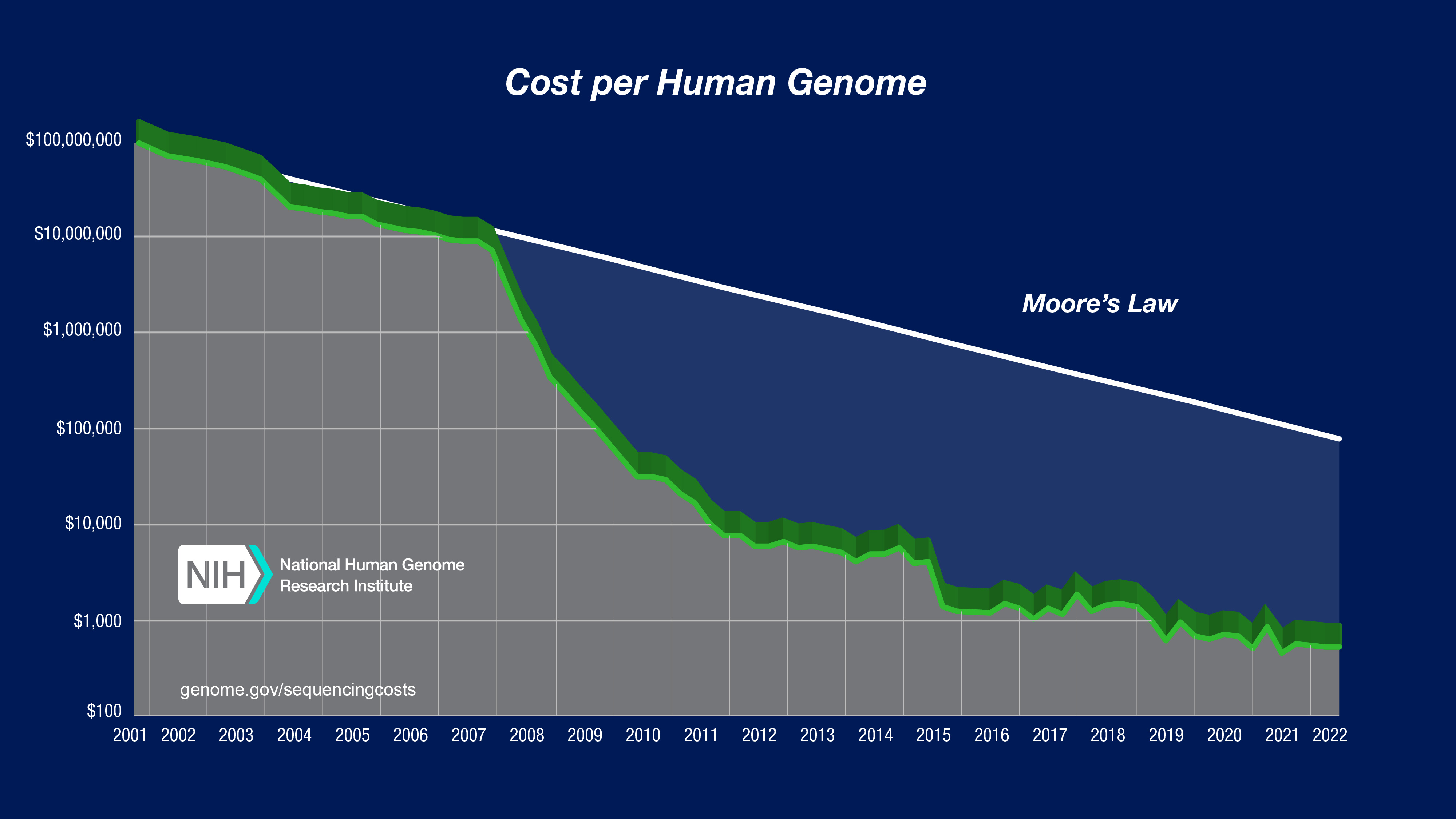
NHGRI's "Cost per Genome" chart, plotted against a Moore's Law reference line. Data through 2022. Source: genome.gov/sequencingcostsdata.
Attention Hits the Same Wall
The attention work rhymes with this almost uncomfortably.
Dense attention asks whether every token should interact with every other token. The trouble is that this scales quadratically (double the context and you quadruple the work), so it gets expensive fast, expensive the way the first genome was expensive, in money and in time. It's the wall that decides how much a model can hold in mind at once, which is why so much effort is going into getting around it. The response emerging now is the familiar one. Don't read everything. Attend only to the parts that carry the most meaning for the sentence in front of you, nearby tokens, or a chosen few. The newest of these approaches claim order-of-magnitude efficiency gains at long context, though whether they hold up at the frontier is still contested, and the contest is exactly the interesting part: the open question is whether the dropped context was carrying something you only notice once it's gone. The same practical question, asked again: do we really need all of it?
The Belief That Follows the Practice
And it'll work. That's the part I want to be clear about. The exome was a good idea; subquadratic attention is a good idea. Reading less to get most of the value at a fraction of the cost is, right now, exactly the right call. The same way it was for sequencing.
The only thing I'd flag is the belief that tends to follow the practice.
Listen to how people are starting to talk. Maybe most of those interactions are redundant. Maybe most context is noise. Maybe the stuff we're dropping was never carrying much to begin with. That's not a claim about cost anymore. That's the junk-DNA move. Taking the thing we can't currently afford to attend to and quietly deciding it wasn't worth attending to.
What I Don't Know Yet
I don't know whether language has a ninety-eight percent. Maybe the dropped interactions really are redundant and sparse attention is just efficient, full stop. I'm not predicting a hidden operating system buried in the tokens we're throwing away. I genuinely don't know.
What I know is that a field did this once. It made a good, necessary compromise, got productive inside it, and slid from "we can't afford to look at the rest" to "the rest isn't worth looking at," and stayed there until the cost came down enough to go check. When it finally checked, the junk turned out to be the part that ran the show.
Subquadratic attention is the exome. Useful, viable, correct for the moment. The question is what we'll find in the other ninety-eight percent once it's cheap enough to look. And whether we'll have talked ourselves out of looking before we get there.
Related Articles

How to Think About AI Agents
RAG Is an Architecture, Not a Feature
Building Your First LLM Application

Neural Networks Got Too Big to Read - Now We Sequence Them

The C++ Renaissance
